Οι ενδιαφερόμενοι developers μπορούν να επωφεληθούν από την τεχνολογία αναγνώρισης εικόνας της Google, η οποία χρησιμοποιεί τεχνητή νοημοσύνη, και να την ενσωματώσουν στα δικά τους προϊόντα.
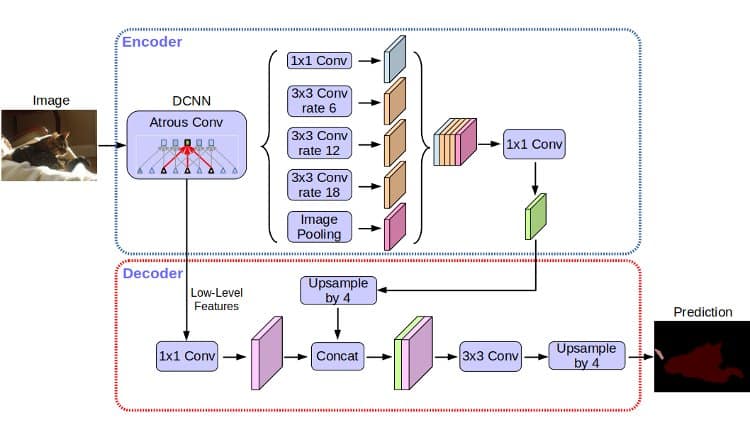
Όταν αναφερόμαστε στη σημασιολογική τμηματοποίηση της εικόνας, εννοούμε τη διαδικασία κατηγοριοποίησης των pixel μιας εικόνας με βάση την αντιστοίχιση τους με μία σημασιολογική έννοια. Με τον τρόπο αυτό, τα pixel σε μια εικόνα τιτλοφορούνται ανάλογα με τη συμμετοχή τους σε αυτή ως “δρόμος”, “ουρανός”, “σκύλος”, “γάτα”, “άνθρωπος”, κτλ. Το ενδιαφέρον μας για τη διαδικασία προκύπτει από την απόφαση της Google να διαθέσει το πλέον πρόσφατο μοντέλο τμηματοποίησης της εικόνας ως open source. Οι ενδιαφερόμενοι developers μπορούν να επωφεληθούν από την εν λόγω τεχνολογία για την αναγνώριση εικόνας της Google, η οποία χρησιμοποιεί τεχνητή νοημοσύνη, και να την ενσωματώσουν στα δικά τους προϊόντα.

Παρόμοια εφέ για την ανασύνθεση του βάθους της εικόνας χρησιμοποιούνται στα Google Pixel 2 και Pixel 2 XL smartphones, όπως και σε τηλεοράσεις για το 2018 της LG.

Η μοντελοποίηση, γνωστή ως DeepLab-v3+, απαιτεί μεγαλύτερη ακρίβεια από άλλες τεχνικές που χρησιμοποιούνται στην αναγνώριση εικόνας.


Όπως λέει η Google, η ακρίβεια που έχει επιτευχθεί στη σημασιολογική τμηματοποίηση της εικόνας βασίζεται στα συνελικτικά νευρωνικά δίκτυα, και οι επιδόσεις που σήμερα επιτυγχάνονται ήταν ακόμη και δύσκολο να τις φανταστεί κανείς πριν μόλις πέντε χρόνια.
Θυμίζουμε ότι το περασμένο καλοκαίρι, η Sony διέθεσε δωρεάν, ως open source, τη δική της Κονσόλα Τεχνητής Νοημοσύνης.
Περισσότερες πληροφορίες είναι διαθέσιμες στο Google Research Blog
- Tags: Digital Imaging, Google